dependency injection
What is dependency injection?
In object-oriented programming (OOP) software design, dependency injection is the process of supplying a resource that a given piece of code requires. The required resource, which is often a component of the application itself, is called a dependency.
When a software component depends upon other resources to complete its intended purpose, it needs to know which resources it should communicate with, where to locate them and how to communicate with them.
One way of structuring the code is to map the location of each required resource. Another way is to use dependency injections and have an external piece of code assume the responsibility of locating the resources. Typically, the external piece of code is implemented by using a framework, such as the Spring Framework for Java applications.
Dependency injections are useful to create loosely coupled programs, while also following the SOLID software design principles. This helps improve the reusability of code, while also reducing the frequency of needing to change a class, a template of the methods or variables in an object.

The 4 roles of dependency injection
Four roles in dependency injection include services, clients, interfaces and injectors.
- Services are what end users employ. A service can be any class that has functionality. Any object can be either a service or client. Which one they are depends on the role the object has in an injection.
- Clients, software components that request something, are what use the service. A client can be any class that uses a service.
- Interfaces break dependencies between lower and higher classes. Interfaces are used by a client and are implemented by a service.
- Injectors introduce a service to a client. They create a service instance and then insert the service into a client. The injector can be many objects working together.
These roles -- minus the injector -- are also used when implementing the dependency inversion principle.
What is dependency injection used for?
Dependency injection is used to make a class independent of its dependencies or to create a loosely coupled program. Dependency injection is useful for improving the reusability of code. Likewise, by decoupling the usage of an object, more dependencies can be replaced without needing to change class.
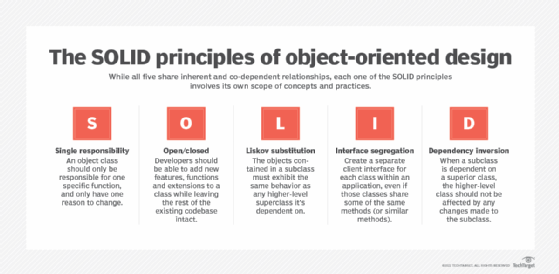
Dependency injection also aids in following the SOLID principles of object-oriented design. There are five aspects of OOP, with each letter representing a principle:
- Single responsibility.
- Open/closed.
- Liskov substitution.
- Interface segregation.
- Dependency inversion.
None of these principles are exclusive, as some of these represent multiple strategies that pursue a single goal. Or, in other cases, adherence to one SOLID practice may naturally lead to another.
Advantages of dependency injection
Dependency injection can be useful in the following cases:
- Dependency injection relieves various code modules from the task of instantiating references to resources and enables dependencies -- even mock dependencies -- to be swapped out easily. By enabling the framework to do the resource creation, configuration data is centralized, and updates only occur in one place.
- Injected resources can be customized through Extensible Markup Language files outside the source code. This enables changes to be applied without having to recompile the entire codebase.
- Programs are more testable, maintainable and reusable. This is possible because the client's knowledge of how its dependencies are implemented is removed.
- It enables developers to work on more. Developers can create classes independently that still use each other. They only need to know the interface of the classes.
- Dependency injection helps in unit testing directly as well. It can externalize configuration details into configuration files. This enables the system to be reconfigured without recompiling.
Disadvantages of dependency injection
However, dependency injection can sometimes come with negatives -- for example:
- Dependency injection makes troubleshooting difficult, as a great deal of code is pushed into an unknown location that creates resources and distributes them as needed across the application.
- Debugging code when all objects that are misbehaving are buried in a complicated third-party framework can be frustrating and time-consuming.
- Dependency injection can slow integrated development environment automation, as dependency injection frameworks use either reflection or dynamic programming.
Examples of dependency injection
When a client requires other components in order to successfully carry out its intended purpose, the client must know what resources are needed, where to locate them and how to communicate with them. One way of structuring code is to embed the logic for locating resources in each client. This tightly coupled approach can be problematic, however, because, if a resource should change location, then the embedded code must be rewritten.
For example, when a user clicks a button, the event creates a new instance of a business logic layer, and one of the event's methods is called. Within that method, a new instance of a data access layer class is also formed, and one of its methods is called. In turn, this method makes a database query.
Another way to structure the code is to have clients declare their dependency on resources and enable an external piece of code to assume the responsibility for instantiating and configuring software components and their dependencies. The external piece of code, which is decoupled, can be hand-coded or implemented with a special software module called a dependency injection container or dependency injection framework.
Essentially, the container or framework provides a map of the dependencies a client might need and logic for adding new dependencies to the map.
These relationships are summed up in the dependency inversion principle, which states, "High-level modules should not depend on low-level modules; both should depend on abstractions. Abstractions should not depend on details. Details should depend upon abstractions."
Methods of dependency injection
There is more than one way to employ dependency injection. The most common way is using constructor injection, which requires that all software dependencies be provided when an object is first created. However, constructor injection assumes the entire system is using this software design pattern, which means the entire system must be refactored at the same time. This is difficult, risky and time-consuming.
An alternative approach to constructor injection is service locator, a pattern that software designers can implement slowly, refactoring the application one piece at a time as convenient. Slow adaptation of existing systems is better than massive conversion efforts. So, when adapting an existing system, dependency injection via service locator is the best pattern to use.
There are those who criticize the service locator pattern, saying it replaces the dependencies rather than eliminating the tight coupling. However, some programmers insist that, when updating an existing system, it is valuable to use the service locator during the transition, and when the entire system has been adapted to the service locator, only a small additional step is needed to convert to constructor injection.
What is inversion of control?
Inversion of control (IoC) is a software design principle that states a class should be configured by another class from the outside, as opposed to configuring dependencies statically. It is the fifth principle of SOLID and asserts a program can benefit in pluggability, testability, usability and loose coupling if the management of an application's flow is transferred to a different part of the application. When interactions occur that need custom business logic, an IoC framework invokes code provided by the developer -- this is the inversion aspect.
Ruby on Rails is an example of IoC in an application framework. The use of event-based user interfaces instead of ones controlled by procedural code would be considered an example of IoC.
Inversion of control vs. dependency injection
While there is some confusion and debate as to the relationship between inversion of control and dependency injection, the latter is generally considered one specific style of the former.
According to Martin Fowler, chief scientist at Thoughtworks, the confusion arises due to the rise of IoC containers. "The name is somewhat confusing since IoC containers are generally regarded as a competitor to Enterprise JavaBeans, yet EJB uses inversion of control just as much -- if not more," according to Fowler.
Dependency injection describes a specific use case of IoC -- one where a container provides a configurable application context that creates, starts, catches and manages pluggable objects.
Types of dependency injection
There are several different styles of dependency injection:
- Interface injection. An injector method, provided by a dependency, injects the dependency into another client. Clients then need to implement an interface that uses a setter method to accept the dependency.
- Constructor injection. An injector provides a dependency using a client class constructor. It is used when a class object is created.
- Setter injection. An injector provides a dependency using the setter method, which sets and modifies the value of a class's private instance variable.
- Method injection. A client class is used to implement an interface. A method then provides the dependency, and an injector uses the interface to supply the dependency to the class.
Learn more about how dependencies can be a problem in microservices, in particular, by creating circular dependencies.






