How a SaaS provider made microservices deployment safely chaotic
Remind was blindsided by performance issues with its microservices-based SaaS, until the company decided to sabotage its own product -- at scheduled times, in staging -- with a different kind of test.
Chaos engineering helps enterprises expect the unexpected and reasonably predict how microservices will perform in production. One education SaaS provider embraced the chaos for its microservices deployment, but it didn't jump in blindly.
San Francisco-based Remind, which makes a communication tool for educators, school administrators, parents and students, faced a predictability problem with its SaaS offering built on microservices. While traffic is steady during most of the year, back-to-school season is extraordinarily busy, said Peter Hamilton, software engineer at Remind.
"We [were] the No. 1 app in the Apple App Store for two weeks," he said.
Unforeseen microservices dependencies caused performance degradations and volatile traffic patterns in production. Remind determined that a microservices architecture on cloud resources was not enough alone to scale and maintain availability.
"Using a microservices architecture is about decoupling the application teams to better achieve the benefit of iteration [from CI/CD] using the agility that cloud provides," said Rhett Dillingham, senior analyst at Moor Insights & Strategy. The fewer developer dependencies, the faster projects move. But speed is only half of the picture, as Remind discovered; microservices add deployment complexities.
Peter Hamilton
"Once you're at scale with multiple apps using an array of microservices as dependencies, you're into a many-to-many relationship," Dillingham said. The payoff is development flexibility and easier scaling than monolithic apps. The downside is significant debugging and tracing complexity, as well as complicated incident response and root cause analysis.
Expect the unexpected
Remind overhauled its microservices deployment approach with chaos engineering across the predeployment staging step, planning and development. Developers use Gremlin, a chaos engineering SaaS tool, for QA and to adjust microservices code before it's launched on AWS. Developers from email, SMS, iOS and Android platforms run Gremlin in staging against hypothetical scenarios.
Remind's product teams average one major release per month. Hamilton noted that requests take tens of microservices to complete. Remind uses unit and functional tests, user acceptance testing and partial release with tracking, but chaos engineering was the missing piece to simulate attacks and expose the chokepoints in the app design.
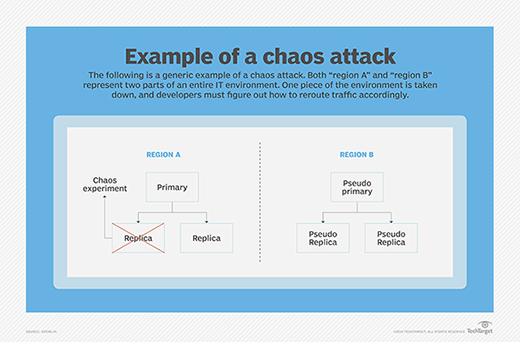
This example chaos engineering experiment will kill the replica database to test if failover to a new region works and behaves as expected.
Remind's main focus with chaos engineering is to interfere with network requests, Hamilton said. The path for requests through multiple microservices is hard to determine and plan for without heuristic testing, and Remind's microservices deployments ran into cascading issues because any increased latency downstream causes problems, Hamilton said. Database slowdowns overload web servers, requests queue up and the product sends out error messages everywhere.
"We're still learning how chaos affects how you do development," he said. Gremlin recommends development teams run the smallest experiment that yields usable information. "People assume the only way to do chaos engineering is to break things randomly, but it's much more effective to do targeted experiments where you test a hypothesis," said Kolton Andrus, CEO of Gremlin.
Remind's goal is to ensure its product degrades gracefully, which takes a combination of development skills and culture. Designers now think about error states, not just green operations, a mindset that emphasizes a clean user experience even as problems occur, Hamilton said.
Remind explored several options for chaos engineering, including Toxiproxy and Netflix's Chaos Monkey. It selected Gremlin because it did not want to build out a chaos engineering setup in-house, and it wanted a tool that fit with its 12-factor app dev model.
Chaos vs. conventional testing
Chaos is about finding the unexpected, Andrus said, up a level from functional testing, which ensures the expected occurs.
Unit testing of interconnections breaks down once an application is composed of microservices, because so many individual pieces talk to each other, Andrus said. Chaos engineering tests internal and external dependencies.
Chaos engineering is the deployment and operations complement to load tests, which help tune the deployment environment with the best configurations to prevent memory issues, latency and CPU overconsumption, said Henrik Rexed, performance testing advocate at Neotys, a software test and monitoring tool vendor. In particular, load tests help teams tailor the deployment of microservices on a cloud platform to take advantage of elastic, pay-as-you-go infrastructure and cloud's performance and cost-saving services.
Remind is particularly aware of the cost dangers from degraded performance and uses chaos engineering to model its resource consumption on AWS in failure modes. "You don't want bad code to impact infrastructure demand," Rexed said. And microservices are particularly vulnerable to outrageous cloud bills, because each developer's or project team's code is just one difficult-to-size piece of a massive puzzle.
Of course, if you really want to test end-user experience on a microservices deployment, you can do it in production. "As the more advanced development teams running microservices take more operational ownership of the availability of their apps, it is expected that they are proactively surfacing bottlenecks and failure modes," Dillingham said. But is it worth risking end users' experience to test resiliency and high availability?
Some say yes. "No matter how much testing you do, it's going to blow up on you in production," said Christian Beedgen, CTO of Sumo Logic, which provides log management and analytics tools. "If nothing is quite like production, why don't we test [there]?"
That was one of the original goals of testing: to surprise people.
Hans BuwaldaCTO, LogiGear
Testing can leave teams to look all over for the wrong problem or look for the right problem but simply miss it, Beedgen said. QA and unit tests are necessary but don't ensure flawless deployment. The goal is to put code in production with blue/green or canary deployment to limit the blast radius, monitor for deviations from known behavior and roll back as needed.
Remind is not ready to bring chaos into its live microservices deployment. "We're conservative about the things we expose production to, but that's the goal," Hamilton said. Chaos in production should have limits: "You don't want a developer to come along and trigger a CPU attack," he said. A nightmare scenario for the SaaS provider is to huddle up all the senior engineers to troubleshoot a problem that is actually just an unplanned Gremlin attack.
Monitor microservices deployments
While Remind prefers to blow up deployments in staging rather than production, it uses the same monitoring tools to analyze attack results. Remind is rolling out Datadog's application performance management (APM) across all services. This upgrade to Datadog's Pro and Enterprise APM packages includes distributed tracing, which Hamilton said is crucial to determine what's broken in a microservices deployment.
Generally, application teams depend much more on tooling to understand complex architectures, Beedgen said. Microservices deployment typically is more ephemeral than monolithic apps, hosted on containers with ever-evolving runtimes, so log and other metrics collection must be aware of the deployment environment. Instead of three defined app tiers, there is a farm of containers and conceptual abstractions, with no notion of where operational data comes from -- the OS, container, cloud provider, runtime or elsewhere -- until the administrator implements a way to annotate it.
Microservices monitoring is also about known relationships, Beedgen said. For example, an alert on one service could indicate that the culprit causing performance degradation is actually upstream or downstream of that service. The "loosely coupled" tagline for microservices is usually aspirational, and the mess of dependencies is apparent to anyone once enough troubleshooting is performed, Beedgen said.
Chaos engineering is one way to hone in on these surprising relationships in independent microservices, rather than shy away from them. "That was one of the original goals of testing: to surprise people," said Hans Buwalda, CTO of software test outsourcing provider LogiGear. In an Agile environment, he said, it's harder to surprise people and generate all-important unexpected conditions for the application to handle.


 Peter Hamilton
Peter Hamilton