Part of:Monolith to microservices: A migration roadmap
Decomposing a monolithic database for microservices
When breaking up a monolith, it's critical to decompose your database alongside your new distributed services. We explore how to do this and avoid creating a distributed monolith.
During a migration from a monolith to a microservices architecture, databases are often an afterthought. Some assume the transition merely involves a reorganization of application logic while the underlying data remains untouched. However, following this path can lead to an awkward mix of a monolith and microservices: a distributed monolith.
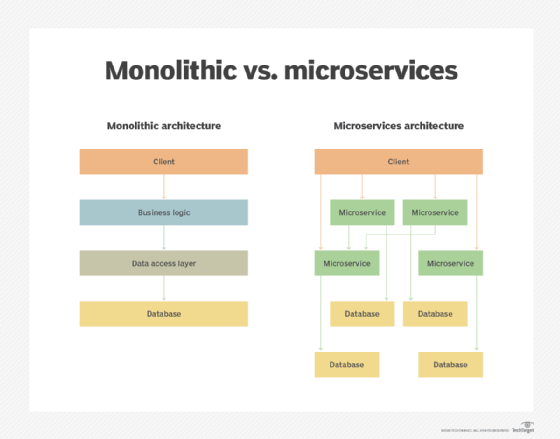
A microservices model elicits a profound change in infrastructure and data storage. Just as the services are pulled out of a legacy application and given independence, teams need to also take their underlying database and break it up into service-specific data sources.
Let's look at how a microservices migration impacts database management and explore steps for database decomposition.
The database per service pattern for microservices
In a microservices architecture, large data lakes need to transform into distributed databases that align to specific services. Doing so creates a necessary separation of concerns between the individual services that only need to access a specific part of the original database. This also helps the teams managing their own set of services maintain the independent control they need.
Following the model recommended by Praful Todkar, monolithic database decomposition needs to happen in tandem with the services they support -- sometimes referred to as a database per service pattern. This should be a gradually phased process, and requires teams to:
Separate out a single service from the monolith and route traffic to it;
Separate a table within the same database to align to that service;
Create a new, smaller database alongside that table and route traffic to it; and
Eliminate the previous data and schema from the original database.
Microservices vs. monolithic architecture structure
Separating the service and table
Restructuring an entire database at once during a microservices migration is a bit like trying to drive a car and change its tires at the same time. Following this path can lead to failures both big and small, as you increase your chances of losing data or breaking functionality.
Instead, start with a small change by making logical separations between the legacy architecture and the new microservices. Once you have selected a service to remove from the monolith, create a new data table (or tables) that contains only the data that the new service requires.
Restructuring an entire database at once during a microservices migration is a bit like trying to drive a car and change its tires at the same time.
During this step, clear routing rules are essential. Teams need to first reroute traffic from the monolithic application to the new microservice. Then, they must transfer pieces of the old monolithic database to the table, which will ultimately frame the new database. All this requires modern networking capabilities, such as the service mesh approach enabled by tools like Istio.
Parity is also critical when it comes time to transform the separated table into a new distributed database. Ensure that the data in both the old and new database is sufficiently synchronized. Once data parity is confirmed, delete the tables and old data from the previous database.
Use schemas for clarity, but not as a crutch
Schemas are collections of metadata that describe the structure of data within a database. Some teams prefer to organize data by schemas, creating one exclusive database schema per service instead of an entire database. There is an arguable benefit to this approach, since there will be fewer databases to manage and more uniformity between them.
However, this practice lands dangerously close to the monolithic data lake model that we want to move away from. When given a choice, developers and architects tend to gravitate toward the familiar, even if it seems objectively counter-productive. Make compromises and follow the schema-per-service approach. But remember: Whenever possible, it's best to have a dedicated database for each service rather than rely on overarching schemas.
The best part of microservices is the freedom it gives you to allocate dedicated databases to some services and use shared databases for others. That decision typically rests upon both the importance of the service and the type of data it handles. Team structure also comes into play here. Some services will demand strict autonomy from the team managing them, and others are better off shared across multiple teams.
Choose the best database for microservices
Typically, monoliths are built on one large relational database. When migrating to microservices, choosing which database to adopt for the new architecture is a huge decision.
Each type of database model is best suited for particular kinds of data management needs. For instance, key-value and columnar databases will work best for structured data, graph for semistructured data, and document store for unstructured data.
Remember that read/write speeds vary among each type of database and the vendor tools that surround them. Run tests using sample data before committing to any one database type or tooling set. For instance, services that need real-time performance will require a database with robust in-memory performance.
Although organizations are migrating to microservices, relational databases will not disappear anytime soon. For various reasons, many applications have parts that simply perform best in a legacy architecture and will depend on the old monolithic database to function. The good news is that microservices support this polyglot model of database management. As such, don't try and force every part of an application out of the monolith just because other services are moving to microservices.